

Bits and Paradoxes #30
Research, Cognitive Blindspots and Frustration; A hypothesis is a liability

Hi,
Nothing much! I’ve been stuck in a loop of boredom, loneliness, and procrastination. A deadly combo I guess.
This time I want to spark a conversation about "research", especially two modes: exploration and testing. Also, about cognitive blindspots.
This is a long-form. Grab a cup of coffee (or water). Or better, save it to read later. I use getpocket to save anything.
I)
When we think of "research", we imagine a bunch of people with white coats, working in a lab, with fancy instruments, a chalkboard with heavy maths, trying to find something.
This has been the norm for a lot of scientific works: we need an environment with good resources, collective intelligence to think heavily on the problems at hand, and systematically come to a conclusion.
A lot of large-scale projects ranging from the Manhattan Project to the Large Hadron Collider, LIGO, Neuralink, to Open AI should inevitably have such scenes of lab, white-coat people, and complex instruments, especially when the stake is very high.
However, things are changing. We have a lot of emerging domains where we can see that the meaning of research is shifting towards independent small-scale groups.
Groups trying to do predictive modeling of user behavior
Groups trying to extract information from unstructured documents
Groups working on cognition
Groups working on recycling
Groups working on making eco-friendly products
…
The list continues. (See... even when I think about “research”, I can only think about those large-scale projects! Another cognitive bias…)
What is research?
To "do research" is to systematically investigate problems and formulate plans to make some decision. That decision can be conclusive or inconclusive.
II)
When I say "I am doing research on X", it means that I am investing a significant amount of time to "see" what sort of things connect to X. (Or perhaps I can connect to…)
These connections can be anything:
Existing works and solutions
Inconclusive research
To-be explored in the future
Controversies to existing solutions.
Imagine an insignificant, frustrated human. Staring at the Linux terminal. Existential crisis. An algorithm staring back, mocking. Probably, lonely!
III)
Let's try to see two scenarios while approaching a problem/research.
I am going to use the terms “problem” and “research” synonymously for the rest of the essay. Please bear with that.
a) The problem (domain) is new
Here, I encounter a brand new problem to solve, as a result of which I am haunted by one particular question: "How the fuck should I start?”
I spend an absurd amount of time "thinking" about the problem hoping that staring at the abyss will solve it. This situation is often phrased as the [[Cold Start Problem]] because you are new, naive, and unknown to the problem. [2]
The Cold Start Problem also relates to [[Analysis Paralysis]], an overthinking situation that can halt your further decision-making process. You are paralyzed because either there are a lot of ideas or there’s a scarcity.
Even if you had an iota of ideas, you'd get stuck soon or just randomly bump into many topics without having any connections.
b) Existing problem
In this scenario, I encounter an existing problem I had previously worked on. So I already have some plans to approach it.
For instance, applying image processing techniques to different image domains such as face recognition, document extraction, and such. The outputs (conclusions) can differ in these, but the fundamental way of approaching the problem is similar. I already have a sense of direction, a well-formed idea I need to execute.
The cold start problem is already solved here. All you have to do is execute your ideas in this phase. The plan might work or might not. This is generally phrased as hypothesis testing (testing the ideas).
Rest of the essay, “idea” and “hypothesis” are used synonymously.
IV) Night Science, Day Science
As I presented previously the case of a new problem and the existing one, they actually have legit terms: Night Science and Day Science respectively.
Night Science
This is an exploration mode for the research where we:
Either wander without any direction
Or encounter/generate ideas for experimentation
It's like finding a black cat in a dark room. Hence the name. (A good metaphor I’d say.)
“Night science wanders blind. It hesitates, stumbles, recoils, sweats, wakes with a start. Doubting everything, it is forever trying to find itself, question itself, pull itself back together. Night science is a sort of workshop of the possible where what will become the building material of science is worked out”
we often have to pop out into the world of night science, where we float between ideas that may be only loosely connected, often moving in associative leaps rather than in logical steps
Day Science
This mode is more oriented towards testing our ideas. These tests are rigorous, focused, and often logically bound. It’s also referred to as hypothesis-driven research.
Say: Do A, B and you might know about C, which can lead to XY.
A lot of research we imagine consists of scientific methods which are oriented more towards the Day Science, such as “people in white-coat working in fancy lab” narrative.
Day science is the one you read about in the news, it is the one we learn about in school, the one captured by the phrase “hypothesis driven”. It’s epitomized by the women and men in white lab coats holding pipettes or looking intently at a computer screen. A day scientist is a hunter who has a clear picture of what she is pursuing.
As I said, things are changing, especially with the rise of “tinkering is thinking” philosophy, where the boundary between tinkering and research is not that clear on the surface. Unknowingly enough, this is in the territory of Night Science.
Night science is (can be) applied in any creative domain.
For instance, when I want to work on new music, I don't immediately "know" what I am producing/creating. So, I explore. Experiment. Randomly fiddle with my guitar. Try to see what works and what doesn't. I might have different melodies in my head. If I get a few good ones, I stick to them and start arranging the instruments and the flow. And then Day Science kicks in. I focus on one thing and streamline it (perfectionism?).
However, the switch can happen to Night Science anytime according to my mood. Say, exploring the genre, tone, and such.
V) Feynman on scientific method
Feynman has given one of the simplest explanations to approach any research. (fanboy alert! haha)
How do we formulate new law?
Guess (Hypothesis)
Compute consequences of the guess
Compare results with nature
Compare with observations if it works
"If it disagrees with experiment - it's WRONG! - That's all there is to it!"
There are two keypoints that I find fascinating with Feynman's explanations:
1) “Correct” doesn't mean it's not wrong.
Suppose you invent a good guess and discover that the consequence agrees with the experiment. Is the theory right?
No! It's not proven WRONG yet.
One of the classic examples is Newton's law of gravitation. For centuries, this law was correct for day-to-day mechanics. However, it failed when tested for the motion of mercury; there was a slight error in calculation for which [[Theory of Relativity]] was able to measure precisely.
This means that being "correct" doesn't mean it's not wrong. It's just temporary. And sometimes that “temporary” can span multiple centuries.
Other examples I can think of right now is the Geocentric model of the universe, Copernican heliocentrism, alchemy, and the likes…
2) You cannot prove a vague theory WRONG.
For instance: when you hear someone say they hate their father, it's not that they actually hate. There are a lot of psycho-emotional factors going on. You'll have to study relationships for a long time to come to the conclusion that they really their father.
References:
VI) A hypothesis is a liability
(This is the most thought-provoking essay I read in the past 2 months, partly because it makes so much sense from my "research" perspective. I highly recommend reading this essay.)
We have already established the difference between Night Science and Day Science. Just for the sake of revision:
While Day Science is about testing existing ideas to form a conclusive narration, Night Science is all about exploring new ideas.
The main point the authors make in this essay is that our assumptions while conducting research, especially during the Day Science mode, have a higher stake in our conclusions.
That is: with Day Science, since we're too focused on testing our hypothesis/ideas, we tend to ignore any other ideas that might be useful.
When we analyze the results of an experiment, our mental focus on a specific hypothesis can prevent us from exploring other aspects of the work, effectively blinding us to new ideas. A hypothesis then becomes a liability for any form of exploration. Because of that "selective attention", it's likely that we can neglect a lot of other hypotheses (which we have discarded or yet to discover).
So, in a sense, Day Science is generally referred to as a "hypothesis-driven" mode that can result in a lot of [[Cognitive Blindspots]]. This selective attention is generally known as [[Inattentional Blindness]].
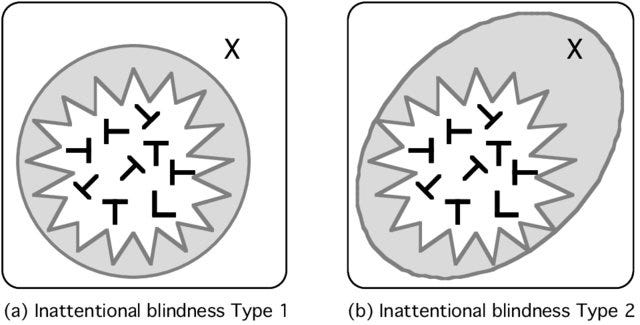
The Gorilla Experiment
An infamous experiment for these blind-spots is [[The Gorilla Experiment]] where observers are asked to count the number of passes players make in a basketball session. Somewhere in the middle, a person with a gorilla costume passes by. Only half of the observers notice it because others are too busy counting the passes.
Modern-ish Version
The authors present a more modern version of this experiment. [0]
Two groups of people are given a task to test a medical dataset:
Group 1 is asked to test/confirm if two variables (BMI and number of steps) are negatively correlated
Group 2 is asked to explore the dataset to generate a conclusion/insight.
However, there's also a hidden (untold) twist. If “BMI vs number-of-steps” is plotted in a graph, it forms the shape of a gorilla (as a tribute to the original gorilla experiment).
Group 1 becomes so narrowly focused on testing the negative correlation hypothesis that they don't realize about the gorilla plot. They don't even care to explore the whole dataset.
Group 2 keeps on exploring the dataset. Only 50% of them are able to see the Gorilla plot.
It’s clear that our selective attention affects the direction of our research, and thus the conclusion we derive thereafter.
Let's take another perspective towards this liability
Just imagine trying to implement someone else's research paper (research idea) that has some conclusions in it. You will know what you're trying to achieve. You can spend a significant amount of time to test many concepts mentioned in the paper.
But, one serious liability here is your selective attention towards replicating the same conclusion. You might not care enough if the author has left out (untouched) other important things.
This first-hand Day Science is creating a serious cognitive blind-spot. You will be cognitively biased towards this paper and the insights it's supposed to generate.
So, it's equally important to let your exploratory mindset to take control. There should be a good balance between the exploration-testing modes.
VII)
No work is complete, in the sense that there is always something the original researchers have left out or didn't touch.
We have to acknowledge the fact that even if we see a lot of research out there, chances are it's incomplete. It might never be complete. So, definitely there's always some room for improvement.
For the past year, I’ve been wearing my hat of skepticism while reading (and implementing) a lot of ML research papers, even those that have good reputations. I feel that these papers create a very superficial narration (conclusion) with “overblown” metrics (say f1 score is 0.98). People feel amazed at seeing the metric presented. But these papers never fully disclose their failures. Seriously! Have you ever read papers from major publications that dive into their failures?
Most of them work on standard (idealized) datasets that don't quite represent the noisy ones we see in real world.
I have realized that presenting the best metric is one thing and using the same ideas in a real situation is another, and often more difficult. The authors from these papers have idealistic assumptions of the data. Hence they fail (and have failed inevitably) when we try to replicate.
One such example of inconclusive results is while trying Graph Neural Networks to highly imbalanced unstructured documents. Just to boost my ego right now, just know that I have read a dozen papers on GNN and every one of them is either too vague or doesn’t mention the imbalances. They perform the experiment on a narrow system, most of which have homogeneous graphs. That is: they perform well on documents with fixed templates. However, in a real scenario, it has a multi-graph setup where documents differ in their structures. These real documents have an enormous amount of background text than the actual key-value pairs we want to extract.
So, our conclusion over Docsumo from these GNN experiments is that GNN performs better on a balanced dataset [1]. Again, that’s our liability currently.
VIII) The art of cognitive blindspots
This is one of my favorite TED talks. Kyle Eschen’s presentation with a lot of dry humour is marvelous.
Kyle is a magician. He performs sleight-of-hand tricks. His fascination towards the sleight-of-hand magicianship stems from his interests in cognitive psychology, especially towards cognitive blind-spots.
"I am interested in all that can go wrong. How an individual can be led astray when certain cognitive vulnerabilities are exploit. I think magic is a great way to explore these things in a borderline ethical fashion..."
"..because there is no secret but the great secret which is: we have gaping blind spots far bigger than our intuition will suggest. To me that's a beautiful idea and the one that animates my interests in this art..."
Few keypoints:
The cognitive blindspot is not of vision but of perception and awareness.
You can be looking right at something and miss it entirely.
We have limited cognitive bandwidth. So, we focus on what's important and filter out any extraneous
IX) So, what do these all mean?
Obviously, a research system such as “hypothesize-compute-compare” isn’t that simple. Any attempt to create a binary interpretation of Day Science / Night Science is superficial in itself.
Often, the line is fuzzy. We aren’t sure where the research is headed, where our current progress belongs to. For this, I have one mental model: frustration-satisfaction.
Frustration-Satisfaction Model
If I spend an absurd amount of time on a topic and still feel frustrated, I know there’s no point in continuing it. Any attempt of further exploration bears no fruits. So, I halt…
This hedonic model works in almost every experiment I try to do. Perhaps, it’s also a measure of my impatience, and how easily I “give in” to the [[Shiny Object Syndrome]].
Anyway, what I am trying to say is that in both Day Science and Night Science, if you feel frustrated, it’s okay to take a break. Sometimes when we are fully focused on a task, our cognitive bias might be a major barrier to our experiments. So, taking a break can help us see things from a bird’s eye perspective.
Even while writing this essay, I am frustrated by a lot of failed experiments because:
(a) I lack “significant” knowledge
(b) the breakthroughs in our fields force us to “up” ourselves to that level
Also, it might not be incorrect to say that the level of frustration of these personal experiments is directly affected by the expectations that stem from consuming a plethora of research “hypotheses” from other people.
“It worked for them. So, why wouldn’t it work for us?”. I guess this narrative sums it all.
Tangent: Our emotions are also our liabilities!
#Related
How do you find the motivation to keep doing ML?
OP has few concerns that are negatively affecting his motivation to work on the ML domain:
a) The world is burning
Not able to do works that can directly impact the world (like climate change?).
b) ML is like shooting in the dark
This relates to Night Science. You have little idea about the blackbox models.
Honestly every time I try to do something principled and grounded in theory, reality slaps me in the face. It just doesn't work. What does work is anticlimactic: training bigger & longer, or arbitrarily tweaking BERT for whatever niche.
c) The field is crowded
The arxiv firehose is overwhelming and (forgive my cynicism) so full of noise. So much gets published everyday, yet so little. There's this crazy race to publish anything, regardless how meaningless that extra layer you added to BERT is. And while I really try to keep my integrity and not write a paper about how I swept the s*** out of those hyperparameters and increased the average GLUE score by a whooping 0.2, realistically I still need to keep up with this crazy pace if I don't want to get fired.
Few responses I really loved in this thread are:
a) Work on something that can create business value by vertically integrating the ML component.
b) Work on applied ML research.
c) One response mentioned switching to [[BERT]] because it improved the performance drastically.
One particular idea that hits close to home is about curiosity-driven experiments:
The only thing that drives me at this point is my own curiosity - i'm not doing projects to get papers published, or to solve practical problems. For instance, right now i'm working on convolutional self-organizing maps for image stylization because image stylization is cool, and self organizing maps are interesting. If you're burned out on doing it professionally, move away from making it a career and do things for fun instead.
Information Extraction from PDFs is one of the most expensive identity functions.
I found this tweet hilariously truthful.
Yup! “Expensive Identity Functions” nails the whole domain. Haha.
#Other
AMA - a short film by Julie Gautier
Hauntingly beautiful. Breathless and liberating. Almost flying.
The making-of video is so beautiful and inspiring.
Ending Thoughts
I love this fragment from Seth Godin which connects to “a hypothesis is a liability” narrative: You don’t have to like the idea, but you can see that it works.
Results don’t care about our explanation. We need a useful explanation if we’re going to improve, but denying the results doesn’t change them.
Beliefs are powerful. They’re personal. They can have a significant impact on the way we engage with ourselves and others. But results are universal and concrete, and no matter how much we’d like them to go away, there they are.
Sigh! That's a long read.
Do share the letter if you found the topic interesting.
Be skeptical. Experiment. Explore. Iterate. Re-iterate.
PS
Oh, BTW! I recently discovered this band [[Tangerine Stoned]], another psychedelic/stoner type. Their L'Urlo Della Strega has been on loop the whole week.
#Footnotes
[0] - This caught my eye. It probably makes a lot of sense while doing statistical analysis of datasets.
[1] - Of course, we have experimented with a lot of weighted cost functions. Tried under-sampling. Other metrics. But that’s that!
[2] - The Cold Start Problem is generally seen in CS, especially in recommender systems. However, this can be generalized to life itself.